- ...
proportionality1
- The variable
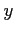 is said to be proportional to the
variable
is said to be proportional to the
variable 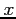 , if there exists a non-zero number
, if there exists a non-zero number 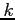 such that
such that 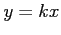 , the
relation is often denoted
, the
relation is often denoted 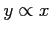 and the constant ratio
and the constant ratio 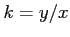 , is
called the constant of proportionality.
, is
called the constant of proportionality.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... dimension2
- A quantity
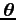 is said to be of
dimension
is said to be of
dimension 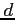 if it may equally well be written
if it may equally well be written
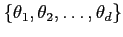 , i.e. it consists of distinct items.
, i.e. it consists of distinct items.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... statistic3
- Let
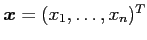 be a vector of observations from a distribution
with parameters
be a vector of observations from a distribution
with parameters
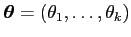 . Let
. Let
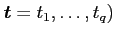 be
be 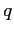 functions of
functions of
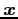 . Then the
set of statistics
. Then the
set of statistics
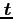 is said to be sufficient for
if the likelihood function
is said to be sufficient for
if the likelihood function
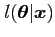 can be
expressed in the form
can be
expressed in the form
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... candidate.4
- If there exists a generated sequence of
values and the current value is
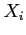 , to generate
, to generate 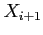 , the process is to
generate a possible value for , for example , and then decide
whether the chain moves to that value or stays in the current value. The value
is called the candidate.
, the process is to
generate a possible value for , for example , and then decide
whether the chain moves to that value or stays in the current value. The value
is called the candidate.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... distribution5
- The current value of the
chain is called the state and the state space of the distribution
is the space consisting of all possible values the distribution
might take.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... 0.01)6
- rnorm(n, m, s)
is the S-Plus command that generates
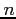 random numbers mean
random numbers mean 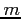 , standard
deviation
, standard
deviation 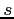 so this generates
so this generates 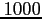 samples using the MCMC sample from the
posterior distribution of the mean as a means vector and the known parameter
samples using the MCMC sample from the
posterior distribution of the mean as a means vector and the known parameter
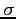 as standard deviation.
as standard deviation.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.