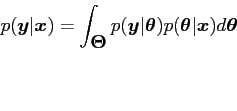Next: Analytic solutions Up: Basic theory Previous: Marginal and conditional densities
Similarly, inference about future observations
![]() , having
observed
, having
observed
![]() is given by the posterior predictive density
is given by the posterior predictive density
where
![]() is the full posterior distribution.
Note that the predictive density
is the full posterior distribution.
Note that the predictive density
![]() provides
inference about
provides
inference about
![]() conditional only on the observed data
conditional only on the observed data
![]() , without reference to any specific value of
, without reference to any specific value of
![]() . This
is in contrast to an estimative approach which might give
. This
is in contrast to an estimative approach which might give
![]() where
where
![]() is a point estimate
(e.g. maximum likelihood).
is a point estimate
(e.g. maximum likelihood).